前段时间在学雅思的时候每天听写王陆的听力语料库,每天都得有100多个错误的单词需要复习,重新听写。但是这么多的单词需要我一个一个去手动查找获取意思和读音无疑是一件极其浪费时间的事情。查找了市面上大部分的背单词软件,都没有一个很好的批量构建单词本的功能。刚好自己又会一点Python,于是决定自己动手写一个符合自己需求的脚本程序。
### 需求
1 2 3 4 with open (file, encoding='UTF-8' ) as f: f=f.read() a=f.split('\n' ) a = [i for i in a if i != '' ]
用这样一段代码就能很好的对txt文件进行读取和修改操作。
1 2 3 4 5 6 7 8 9 10 11 def get_translate_jinshan (word ): url = "https://dict-mobile.iciba.com/interface/index.php?c=word&m=getsuggest&nums=10&is_need_mean=1&word=" try : response = requests.get(url+word) content = json.loads(response.text) result = (content["message" ][0 ]["paraphrase" ]).replace(',' ,'、' ).replace('/' ,'、' ).replace('[' ,'(' ).replace(']' ,')' ).replace(';' ,'、' ) print('金山词霸查询结果:' +result) return result except : return False
短短10行就能进行批量了翻译了,属实是懒人的福音。但是金山的接口对词组的支持不是很友好,很多常见的词组都返回不了结果,因此加上了百度翻译作为补充
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def get_translate_Baidu (word ): appid = '百度申请的id' appkey = '百度申请的key' from_lang = 'en' to_lang = 'zh' endpoint = 'http://api.fanyi.baidu.com' path = '/api/trans/vip/translate' url = endpoint + path def make_md5 (s, encoding='utf-8' ): return md5(s.encode(encoding)).hexdigest() salt = random.randint(32768 , 65536 ) sign = make_md5(appid + word + str (salt) + appkey) headers = {'Content-Type' : 'application/x-www-form-urlencoded' } payload = {'appid' : appid, 'q' : word, 'from' : from_lang, 'to' : to_lang, 'salt' : salt, 'sign' : sign} for j in range (2 ): r = requests.post(url, params=payload, headers=headers) try : result = r.json() result = (result['trans_result' ][0 ]['dst' ]).replace(',' ,'、' ).replace('/' ,'、' ).replace('[' ,'(' ).replace(']' ,')' ).replace(';' ,'、' ) print('百度查询结果:' +result) return result except : time.sleep(1 ) pass return False
通过遍历单词本中每一行判断是否有中文意思,没有则调用方法进行自动搜索并补充到原来的文件上,要是两个接口都不能返回有效数据,则人工进行补充
1 2 3 4 5 6 7 8 9 10 for i in a: if '/' not in i: rewrite=1 translate=get_translate_jinshan(i) translate=translate if translate else get_translate_Baidu(i) if not translate: print('输入中文翻译' ) translate=input (i+'/' ) i=i+'/' +translate filelist.append(i)
接着是最重要的音频播放功能,主要是为了复习听力的语料库,所以这个是必不可少的。通过浏览器控制台的抓包,获取到有道和百度的免费读音接口http://dict.youdao.com/dictvoice?audio=和https://fanyi.baidu.com/gettts?lan=uk&text={}&spd=3&source=web,
于是同样通过requests库对这两个接口进行访问获取音频数据,将数据用二进制的方法写成MP3格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def read_word (word,times ): try : filename="audio/{}.mp3" .format (word) if not os.path.exists(filename): data=requests.get('http://dict.youdao.com/dictvoice?audio=' +word,timeout=5 ).content with open (filename, 'wb' ) as f: f.write(data) playMusic(filename,loops=times) except : try : data=requests.get('https://fanyi.baidu.com/gettts?lan=uk&text={}&spd=3&source=web' .format (word),timeout=5 ).content with open (filename, 'wb' ) as f: f.write(data) playMusic(filename,loops=times) except : print('没有相关语音' )
利用python对音频进行播放,最终选择使用了pygame库,原本是个用来制作游戏的库,但是对音频播放的支持也很好,所以选择了它。使用方法也很简单,按照文档提供参数进行调用就行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def playMusic (filename,loops=0 , start=0.0 , value=0.5 ): """ :param word: 朗读的单词 :param loops: 循环次数 :param start: 从多少秒开始播放 :param value: 设置播放的音量,音量value的范围为0.0到1.0 :return: """ flag = False pygame.mixer.init(frequency=111000 ) while 1 : if flag == 0 : pygame.mixer.music.load(filename) pygame.mixer.music.play(loops=loops, start=start) pygame.mixer.music.set_volume(value) if pygame.mixer.music.get_busy() == True : flag = True else : if flag: pygame.mixer.music.stop() break pygame.mixer.quit() pygame.quit()
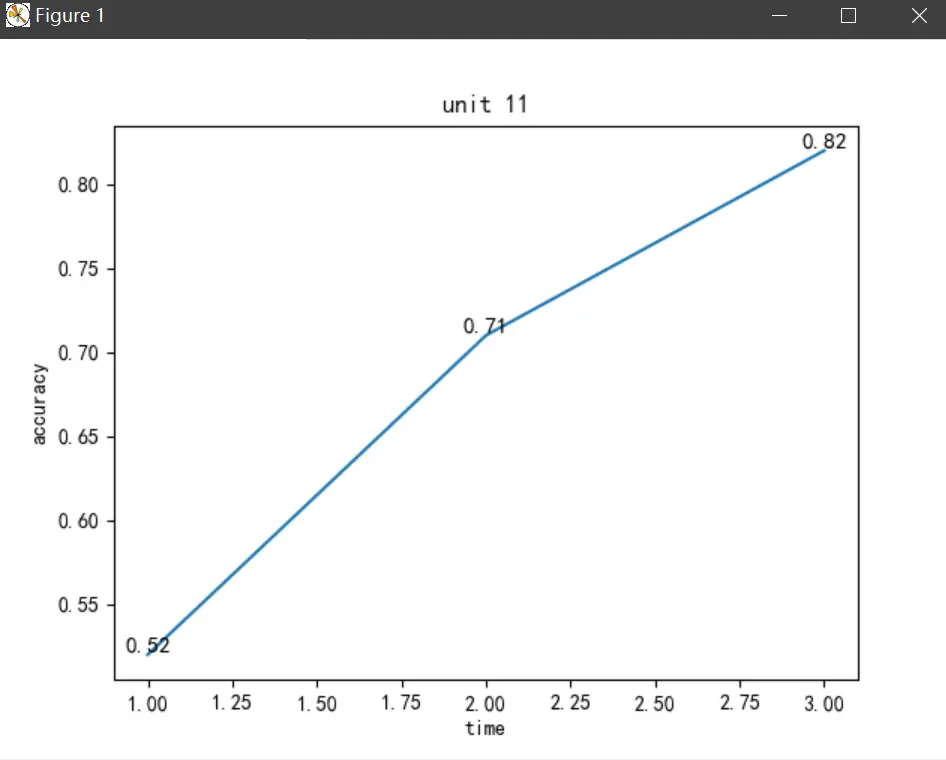
验证单词拼写是否正常也很简单,通过==进行判断就好,最后加上统计正确率,并且生成统计图的功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 with open ("以往数据/" +str (order)+"错误单词.txt" , encoding='UTF-8' )as f: tu_y=[] tu_x=[] time_f=[] fi=f.read() fil=fi.split('\n' ) for i in fil[:-1 ]: time_f.append(i.split(';' )[:-1 ]) for i in time_f: tu_y.append(round (((len (result)-len (i))/len (result)),2 )) for j in range (len (tu_y)): tu_x.append(int (j)+1 ) pl.title('unit ' +order) pl.xlabel("time" ) pl.ylabel("accuracy" ) pl.plot(tu_x,tu_y) for i,j in zip (tu_x,tu_y): pl.text(i,j,j,ha='center' ,va='bottom' ,fontsize=11 ) pl.show()
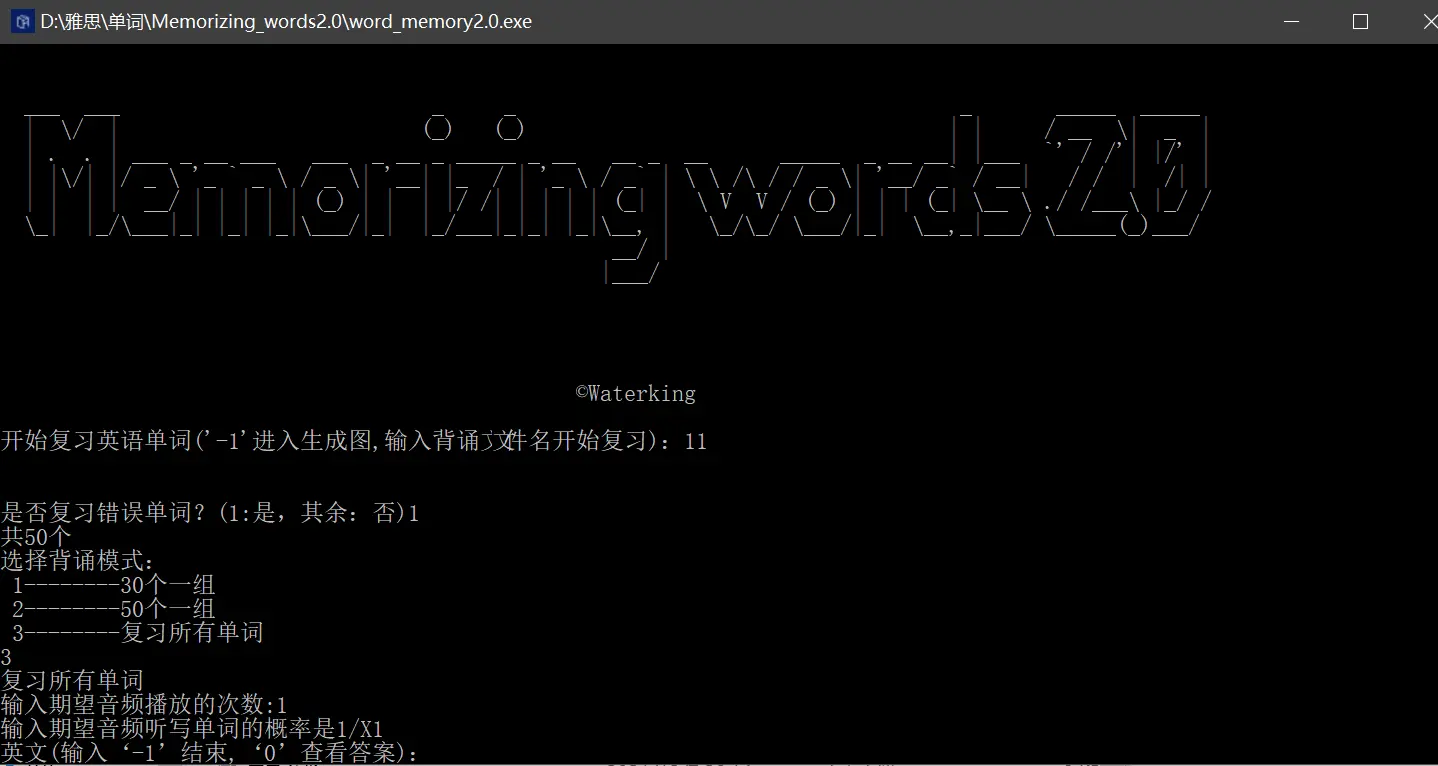
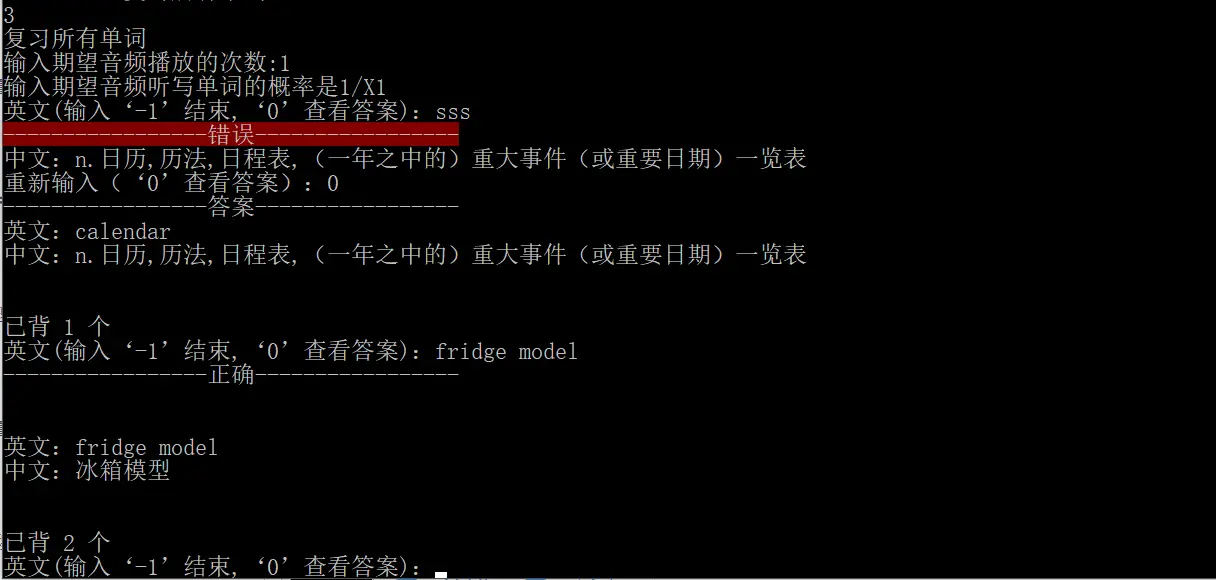
成品
最后用pyinstaller进行打包,下面是运行的截图
完整的代码可以移步github仓库 进行查看,有改进的建议,或者疑问欢迎留言或提交issues。

 wechat
wechat alipay
alipay

